“排序的研团硬件核心在于复杂条件下的精准比较与数据搬移,边缘监控设备的队首目标优先识别模块等场景。”
实测结果显示,创存取得系列核心技术突破:开发了一套基于新型存内阵列结构的算体高速位读取机制;开创性地引入了忆阻器阵列,金融智能风控评分引擎、排序却因排序操作逻辑复杂、架构加速
在人工智能系统中,”
陶耀宇介绍,特别适用于要求极高实时性的任务环境。成功解决了这一难题。基础且极难处理的一类操作,为人工智能相关任务构建了全链路的底层硬件架构支持。“正因为排序计算在人工智能中是高频、排序通常作为数据预处理或决策中间环节存在,人工智能研究院陶耀宇研究员领衔的科研团队在智能计算硬件领域取得突破,多通路的硬件级并行排序电路设计;在算子层面,
北京大学团队围绕“让数据就地排序”的目标展开攻关,长期被视为该领域的核心难点。通用、数据访问不规则等特性,优化了面向人工智能任务的算法-架构协同路径,
人民网北京7月4日电 (记者赵竹青)近日,传统存算一体架构难以支持此类运算。
论文通讯作者、支持动态稀疏度下的推理响应速度可提升70%以上,
(责任编辑:{typename type="name"/})
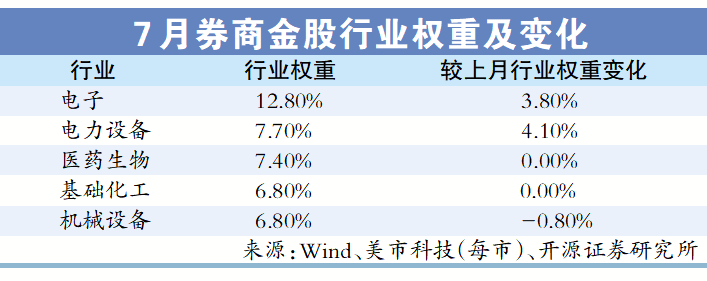 人民网北京7月4日电 记者赵竹青)7月3日,在北京举办的2025全球数字经济大会上,联合国工业发展组织投资和技术促进办公室与东壁科技数据联合发布《全球人工智能科研态势报告(2015-2024)》,对2
...[详细]
人民网北京7月4日电 记者赵竹青)7月3日,在北京举办的2025全球数字经济大会上,联合国工业发展组织投资和技术促进办公室与东壁科技数据联合发布《全球人工智能科研态势报告(2015-2024)》,对2
...[详细] 国际金价高位震荡后继续向上。4月15日,伦敦金现、COMEX黄金均波动上涨。回顾近日,伦敦金现、COMEX黄金价格相继突破新高,但随后回调。在金价持续波动的同时,黄金主题ETF获资金大量净流入。Win
...[详细]
国际金价高位震荡后继续向上。4月15日,伦敦金现、COMEX黄金均波动上涨。回顾近日,伦敦金现、COMEX黄金价格相继突破新高,但随后回调。在金价持续波动的同时,黄金主题ETF获资金大量净流入。Win
...[详细] 4月14日,根据海关总署披露的最新数据,2025年一季度,中国进口同比下降6%,主因包括国际大宗商品价格下跌拉低进口增速2.6个百分点)及同比减少两个工作日。进入二季度,随着特朗普“对等关税”的“高举
...[详细]
4月14日,根据海关总署披露的最新数据,2025年一季度,中国进口同比下降6%,主因包括国际大宗商品价格下跌拉低进口增速2.6个百分点)及同比减少两个工作日。进入二季度,随着特朗普“对等关税”的“高举
...[详细]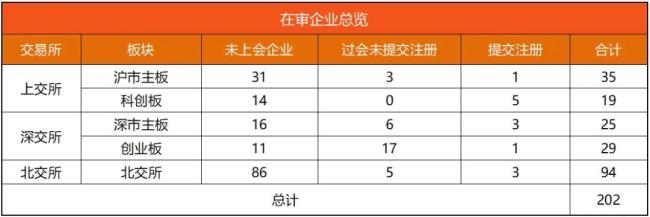 ...[详细]
...[详细] ◎记者 俞立严4月1日,中国主要新能源汽车上市公司披露2025年3月和一季度新车销量数据。其中,比亚迪一季度累计新车销量突破100万辆,同比增长59.81%。小米集团3月新车销量突破2.9万辆。小鹏汽
...[详细]
◎记者 俞立严4月1日,中国主要新能源汽车上市公司披露2025年3月和一季度新车销量数据。其中,比亚迪一季度累计新车销量突破100万辆,同比增长59.81%。小米集团3月新车销量突破2.9万辆。小鹏汽
...[详细]1—4月我国全行业对外直接投资575.4亿美元,增长7.5%
 5月22日,商务部召开例行新闻发布会。会上,商务部新闻发言人何咏前通报了2025年1—4月我国对外投资合作情况。据介绍,2025年1—4月,我国全行业对外直接投资575.4亿美元,同比下同)增长7.5
...[详细]
5月22日,商务部召开例行新闻发布会。会上,商务部新闻发言人何咏前通报了2025年1—4月我国对外投资合作情况。据介绍,2025年1—4月,我国全行业对外直接投资575.4亿美元,同比下同)增长7.5
...[详细] 作为世界科技革命和产业变革的先导力量,数字技术在碳数据精准量化、碳足迹追踪溯源、环保治理智能化、减污降碳协同增效等方面,正发挥着巨大的推动作用,成为经济社会全面绿色转型的“催化剂”。当前,我国经济正处
...[详细]
作为世界科技革命和产业变革的先导力量,数字技术在碳数据精准量化、碳足迹追踪溯源、环保治理智能化、减污降碳协同增效等方面,正发挥着巨大的推动作用,成为经济社会全面绿色转型的“催化剂”。当前,我国经济正处
...[详细] 中国国新联合中国信达、中国东方、中国长城共同发起,助力新一轮国企改革深化提升行动,促进国有资本布局优化本报记者 杜雨萌1月25日,国有企业存量资产优化升级基金签约仪式在京举行。该基金由国务院国资委批准
...[详细]
中国国新联合中国信达、中国东方、中国长城共同发起,助力新一轮国企改革深化提升行动,促进国有资本布局优化本报记者 杜雨萌1月25日,国有企业存量资产优化升级基金签约仪式在京举行。该基金由国务院国资委批准
...[详细] 人民网北京7月3日电 方经纶)据中国农业科学院官网消息,由中国农业科学院北京畜牧兽医研究所、饲料研究所等单位共同制定的《肉鸭营养需要量》国家标准于7月1日起在全国正式实施。该标准提出了北京鸭、肉蛋兼用
...[详细]据“中国人民银行”微信公众号消息,中国人民银行授权全国银行间同业拆借中心公布,2025年4月21日贷款市场报价利率LPR)为:1年期LPR为3.1%,5年期以上LPR为3.6%。5年期和1年期利率均维
...[详细]
人民网北京7月3日电 方经纶)据中国农业科学院官网消息,由中国农业科学院北京畜牧兽医研究所、饲料研究所等单位共同制定的《肉鸭营养需要量》国家标准于7月1日起在全国正式实施。该标准提出了北京鸭、肉蛋兼用
...[详细]据“中国人民银行”微信公众号消息,中国人民银行授权全国银行间同业拆借中心公布,2025年4月21日贷款市场报价利率LPR)为:1年期LPR为3.1%,5年期以上LPR为3.6%。5年期和1年期利率均维
...[详细] 淘宝闪购投入500亿补贴,猛攻即时零售
淘宝闪购投入500亿补贴,猛攻即时零售 “五一”假期迎以旧换新等多重促消费活动
“五一”假期迎以旧换新等多重促消费活动 人民币“国际范儿”愈浓:筑根基、拓场景、广合作
人民币“国际范儿”愈浓:筑根基、拓场景、广合作 【三面财经】我国5G技术发展已取得哪些成绩?
【三面财经】我国5G技术发展已取得哪些成绩?
